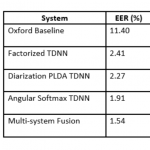
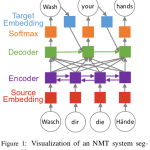
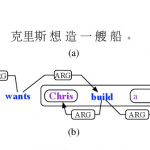
Dr. Peter Viechnicki joins the HLTCOE as its new Director
September 15, 2020
Dr. Peter Viechnicki, a highly respected technologist with extensive experience as a research manager, has been appointed to serve as Director of the Human Language Technology Center of Excellence (HLTCOE). Viechnicki, who joined the University on 15 September, received his PhD in Linguistics from the University of Chicago with a dissertation in phonetics. He brings […]