HLTCOE a Top Performer at VoxSRC
JHU HLTCOE was a top performer in a recent open speaker recognition challenge called VoxSRC, finishing in the top two of more than fifty entries from the international research community. The challenge, hosted by the University of Oxford, was based on the open-source VoxCeleb speech corpus captured from public celebrity videos with automatic speaker labeling using dep face recognition.
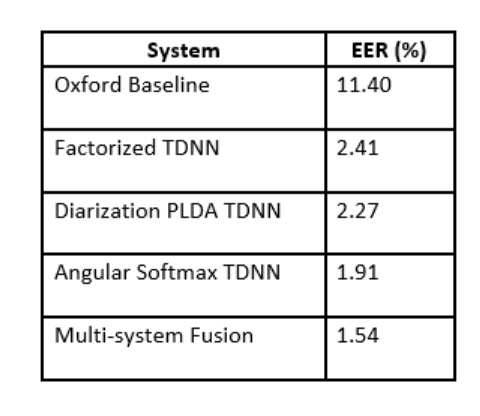
There are two main differences between this challenge and the most recent NIST Speaker Recognition Evaluation (SRE): no explicit domain shift between training and testing data, and very short average audio duration (around 5 seconds). The core of our submission is a Deep Neural Network (DNN) x-vector system with a Time Delay Neural Network (TDNN) architecture, but we used three new variations for this challenge. First, we used a deeper network with residual connections, known as a factorized TDNN, to support robust training of a larger model. Second, we used our most recent x-vector system designed for speaker diarization using short enrollment segments and internal metric learning via Probabilistic Linear Discriminant Analysis (PLDA). Finally, our best-performing system for this task replaced the traditional affine output layer with a cosine similarity approach known as angular softmax with additive margin.
Table 1 below shows the evaluation performance in terms of Equal Error Rate (EER) for the University of Oxford Baseline DNN system and the three systems described above, as well as our four-system fusion which placed second on the official challenge leaderboard.
Along with our colleagues in the international research community, we participated in the VoxSRC Challenge Workshop held in Graz, Austria in September in conjunction with Interspeech 2019.
Table 1: VoxSRC evaluation performance of the University of Oxford
Baseline system and four JHU HLTCOE systems.