Building OCR/NER Test Collections
Named entity recognition (NER) identifies spans of text that contain names. Many researchers have reported the results of NER on text created through optical character recognition (OCR) over the past two decades. Unfortunately, the test collections that support this research are annotated with named entities after OCR has been run. This means that the collection must be re-annotated if the OCR output changes.
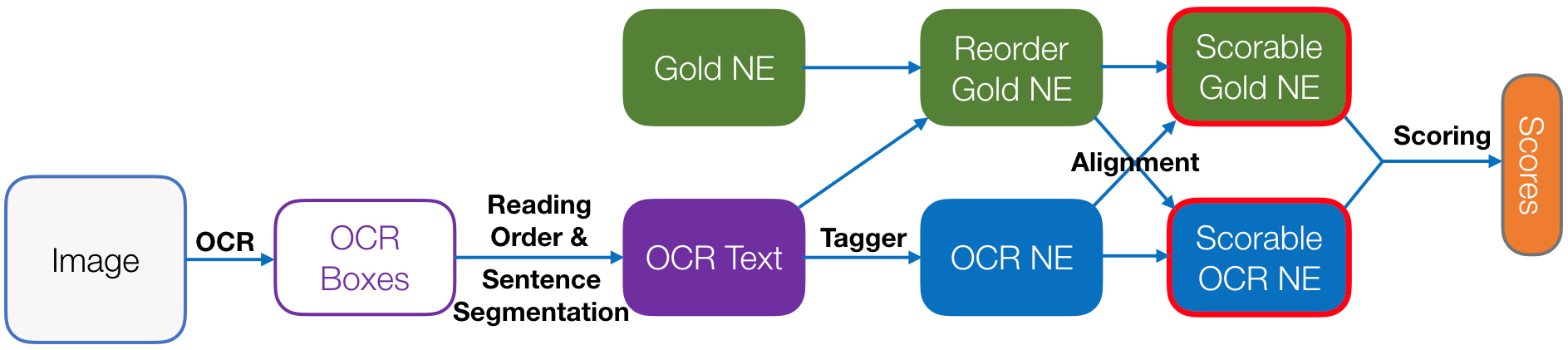
By tying annotations to character locations on the page, the HLTCOE has shown how to build a collection that supports OCR and NER research without requiring re-annotation when either improves. For NER evaluation, the tagged OCR output is aligned to the transcribed ground truth text, and modified versions of each are created and scored. To demonstrate the efficacy of this approach, the HLTCOE has released a collection of Chinese OCR-NER data constructed using the methodology. The collection is available here.
Citation: Dawn Lawrie, James Mayfield and David Etter, “Building OCR/NER test collections.’’ In Proceedings of LREC 2020, Marseille, 2020.